YOLO11 Image Segmentation
This model builds upon the detection model by adding the ability to determine which pixels belong to the target object.

Prepare Model File
The program package we provide includes a file named yolo11n-seg.nb, which is the model file for running YOLO11 image segmentation on the WalnutPi 2B (T527) NPU.
If you want to try converting the model yourself, refer to: Model Conversion Tutorial
Install OpenCV
This tutorial requires the OpenCV library. For installation instructions, refer to: OpenCV Installation
Run Model with Python
WalnutPi 2B v1.3.0 and above provides a packaged YOLO11 Python library.
1. Instantiate yolo11 Class
Instantiate the YOLO11_SEG class by passing the model file path:
from walnutpi import YOLO11
yolo = YOLO11.YOLO11_SEG("model/yolo11n-seg.nb")
2. Run Model - Blocking Mode
Use the run method to run the model and get detection results. It takes 3 parameters:
- Image data, read using OpenCV's image reading method
- Confidence threshold, only detection boxes above this confidence will be returned
- Detection box overlap threshold, the model often hits multiple boxes around an object. If the area overlap between boxes exceeds this value, only the box with the highest confidence is kept, and other overlapping boxes are removed
# Read image
import cv2
img = cv2.imread("image/bus.jpg")
# Detect
boxes = yolo.run(img, 0.5, 0.5)
3. Run Model - Non-blocking Mode
Use the run_async method, which creates a thread to run the model and returns immediately. It takes 3 parameters:
- Image data, read using OpenCV's image reading method
- Confidence threshold, only detection boxes above this confidence will be returned
- Detection box overlap threshold
Non-blocking mode works with the is_running property, which has a value of true or false, indicating whether a run_async model thread is running in the background. If a thread is already running, calling run_async again won't start a new thread. You can also use this property to check if the model thread has finished and results are ready.
Use the get_result() method to return the background recognition result, which is the same as what the blocking run method returns:
import cv2
img = cv2.imread("image/bus.jpg")
yolo.run_async(img, 0.5, 0.5)
while yolo.is_running:
time.sleep(0.1)
boxes = yolo.get_result()
4. Detection Results
Both the run method and get_result method return a list. If nothing is detected in the image, an empty list is returned. Each value in the list represents a detected box, and each box object contains the following properties:
| Property | Description |
|---|---|
| x | x-coordinate of the detection box center |
| y | y-coordinate of the detection box center |
| w | Width of the detection box |
| h | Height of the detection box |
| reliability | Confidence of the detection box, e.g., 0.78 |
| label | Label of the detection box |
| contours | List of all contour point coordinates |
| mask | A single-channel grayscale image; pixels not belonging to the object are 0, pixels belonging to the object are 255 |
Note that label is a number. For example, the official YOLO model was trained with 80 annotated types, so the detected label property will be 0-79.
The following code can be used to output all detected box information:
print(f"boxes: {boxes.__len__()}")
for box in boxes:
print(
"{:f} ({:4d},{:4d}) w{:4d} h{:4d} lbael:{:d}".format(
box.reliability,
box.x,
box.y,
box.w,
box.h,
box.label,
)
)
The mask image can be overlaid on the original image using the following code:
import numpy as np
mask_img = np.zeros_like(img) # Generate a pure black image of the same size as the original
mask_img[box.mask > 200] = (0, 255, 0) # Change pixels with mask value greater than 200 to green
img = cv2.addWeighted(img, 1, mask_img, 0.5, 0) # Overlay mask_img on the original
Example Programs
Image-Based
Read an image for detection and highlight target objects.

'''
Experiment Name: YOLO11 Image Segmentation
Experiment Platform: WalnutPi 2B
Description: Image-based
'''
from walnutpi import YOLO11
import dataset_coco
import cv2
import numpy as np
# [Optional] Allow Thonny remote execution
import os
os.environ["DISPLAY"] = ":0.0"
model_path = "model/yolo11n-seg.nb"
picture_path = "image/000000371552.jpg"
output_path = "result.jpg"
# Detect image
yolo = YOLO11.YOLO11_SEG(model_path)
boxes = yolo.run(picture_path, 0.5, 0.5)
# Draw boxes on image
img = cv2.imread(picture_path)
for box in boxes:
left_x = int(box.x - box.w / 2)
left_y = int(box.y - box.h / 2)
right_x = int(box.x + box.w / 2)
right_y = int(box.y + box.h / 2)
label = str(dataset_coco.label_names[box.label]) + " " + str('%.2f'%box.reliability)
(label_width, label_height), bottom = cv2.getTextSize(
label,
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
1,
)
cv2.rectangle(
img,
(left_x, left_y),
(right_x, right_y),
(255, 255, 0),
2,
)
cv2.rectangle(
img,
(left_x, left_y - label_height * 2),
(left_x + label_width, left_y),
(255, 255, 255),
-1,
)
cv2.putText(
img,
label,
(left_x, left_y - label_height),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
1,
)
mask_img = np.zeros_like(img)
mask_img[box.mask > 200] = (0, 255, 0)
img = cv2.addWeighted(img, 1, mask_img, 0.5, 0)
# Save image
cv2.imwrite(output_path, img)
# Display image in window
cv2.imshow('result',img)
cv2.waitKey()
cv2.destroyAllWindows()
Camera-Based
You can first learn about the USB Camera Usage Tutorial in OpenCV.
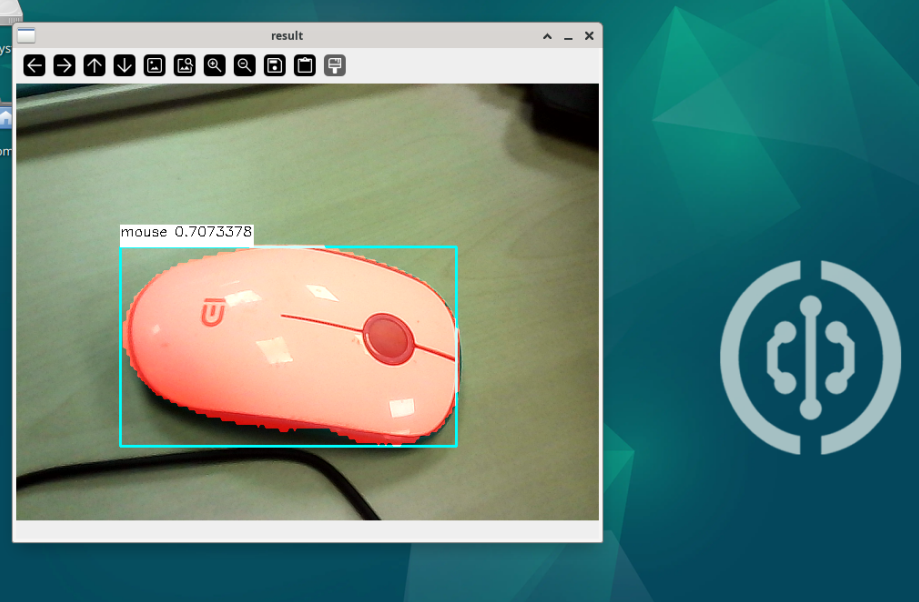
'''
Experiment Name: YOLO11 Image Segmentation
Experiment Platform: WalnutPi 2B
Description: Camera-based
'''
from walnutpi import YOLO11
import dataset_coco
import cv2
import numpy as np
# [Optional] Allow Thonny remote execution
import os
os.environ["DISPLAY"] = ":0.0"
model_path = "model/yolo11n-seg.nb"
# Detect image
yolo = YOLO11.YOLO11_SEG(model_path)
# Open camera and loop to display frames on screen
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
ret, img = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
if not yolo.is_running:
yolo.run_async(img, 0.5, 0.5)
boxes = yolo.get_result()
for box in boxes:
left_x = int(box.x - box.w / 2)
left_y = int(box.y - box.h / 2)
right_x = int(box.x + box.w / 2)
right_y = int(box.y + box.h / 2)
label = str(dataset_coco.label_names[box.label]) + " " + str('%.2f'%box.reliability)
(label_width, label_height), bottom = cv2.getTextSize(
label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1,
)
cv2.rectangle(img, (left_x, left_y), (right_x, right_y), (255, 255, 0), 2)
cv2.rectangle(img, (left_x, left_y - label_height * 2), (left_x + label_width, left_y), (255, 255, 255), -1)
cv2.putText(img, label, (left_x, left_y - label_height), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
mask_img = np.zeros_like(img)
mask_img[box.mask > 200] = (0, 0, 255)
img = cv2.addWeighted(img, 1, mask_img, 0.8, 0)
cv2.imshow("result", img)
key = cv2.waitKey(1)
if key == 32:
break
cap.release()
cv2.destroyAllWindows()